“SenticNet5:Discovering Conceptual Primitives for Sentiment Analysis by Means of Context Embeddings”
—-本文发表于2018年AAAI会议
在这项工作中,我们将sub-symbolic和symbolic AI结合起来,自动地从文本中发现概念原语(conceptual primitives ),并将它们链接到常识性概念和命名实体,在一个新的三层知识表示中进行情感分析。
为了解决目前机器学习(尤其是深度学习)的数据依赖性、实验一致性和过程透明性问题,我们需要联合自顶向下(利用symbolic模型的事实,例如语义网络)的方法和自底向上(利用sub-symbolic方法从数据中推断语法模式)的方法。
SenticNet5为现实世界的物体、动作、事件和人编码了富有表现力和内涵的信息。它不再盲目地使用关键词和单词的共现,而是依赖于与常识性概念相关联的隐含意义。
概念原语的重要性
针对概念级别的情感分析和概念袋(bag-of-concepts)模型,由于自然语言的丰富性和模糊性,传统的语义解析方法和n-gram模型容易产生误差。一个有效的方法是通过泛化语义相关的概念来实现一个自顶向下的方法,比如对于munch_toast和slurp_noodles可以映射到概念原语EAT_FOOD。这种概括背后的思想是,有一组有限的mental primitives来表达受影响的概念,有一组有限的mental combination原则来控制它们之间的相互作用。
发现原语
对于句子S=[w1,w2,…wn],句子被分为3部分:left context:[w1,…wi-1],right context:[wi+1,…wn],target word:[wi]。我们的目的是通过上下文(left context和right context)和target word来找到target word的原语替代。
该部分的框架如下图所示: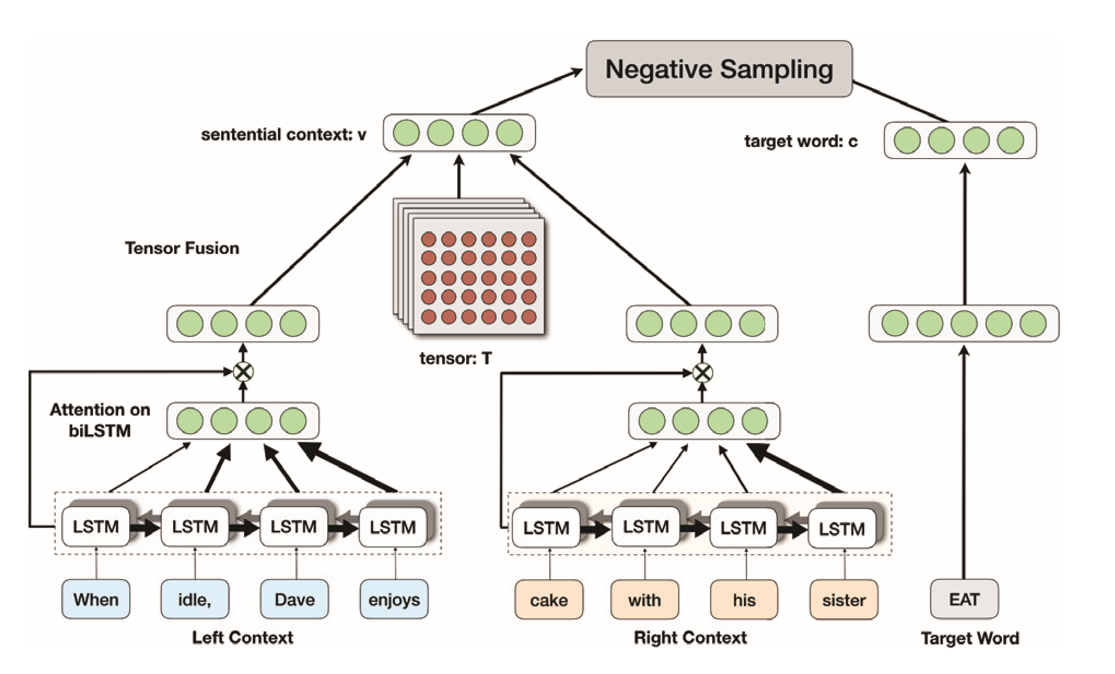
Target Word Representation
对于target word,它的embedding是dm维的向量C,通过如下公式我们得到它的表达c(两层带tanh的全连接):
C1=tanh(WaC+ba)
c=tanh(WbC1+bb)
Sentential Context Representation
对left context和right context 分别采用带注意力机制的BiLSTM(这里的注意力机制是LSTM最原始的注意力机制,不做赘述)得到它们的表达ELC和ERC。为了融合这两部分表达,本文使用一个神经张量网络(neural tensor network)T,T是一个2d x 2d x k维的张量,它在k维空间上执行双线性融合。公式如下:
v=tanh(E’LC T[1:k] ERC+W[ELC,ERC]+b)
对该公式做个简单的说明:首先是E’LC T[1:k] ERC,它是对每个i,1<=i<=k,做E’LC Ti ERC得到一个标量,然后k个拼接成一个k维向量。W是一个kx4d的张量(ELC是2d维的),注意ELC和ERC两个都是列向量而且是竖着拼接的(由于排版和语法问题,我这里的写法有点小问题,实际上[]内应该竖着写,特做说明),b是一个k维向量。这个v就是最后的上下文表达。
负采样
对于每个正确的上下文和目标词表达对,我们根据unigram distribution随机挑选z个负样本,目标函数定义如下:
obj=$\displaystyle \sum_{c,v}{(\log(\sigma(c.v)+\sum^{z}_{i=1}log(\sigma(-c_i.v)))}$
相似性指数
对于上下文信息v和目标词c,替代词b的相似性指数为:dist(b,(c,v))=cos(b,c).cos(b,v)
具体来说,首先,我们提取了ConceptNet5中出现的verb-noun和adjective-noun形式的所有概念。还提取了每个概念的一个示例句子。然后,我们从concept(动词/形容词或名词)中提取一个单词作为目标单词,其余的句子作为上下文。现在的目标是找到在给定上下文中具有相同词性的目标词的替代。
将原语链接到概念和实体
上述的神经网络框架可以发现概念聚类(concept clusters,这块我的理解是具有相同替代词的target word是一类,然后该类的标签是在文本集中出现次数最多的词。但从实现上来说,有一些问题,我暂时还没想明白,先在这留个坑),由于相似性指数,每个概念只属于一个类。这个聚类操作可以将知识图谱从概念层升级到原语层。
SenticNet5是一个三层结构的语义网,自底向上是实体层、概念层、原语层。原语层是基本的状态和动作,概念层是通过语义关系连接常识概念的地方,实体层是命名实体集合,它们通过IsA关系连接到常识概念。
下图是原语INTACT的语义网络:
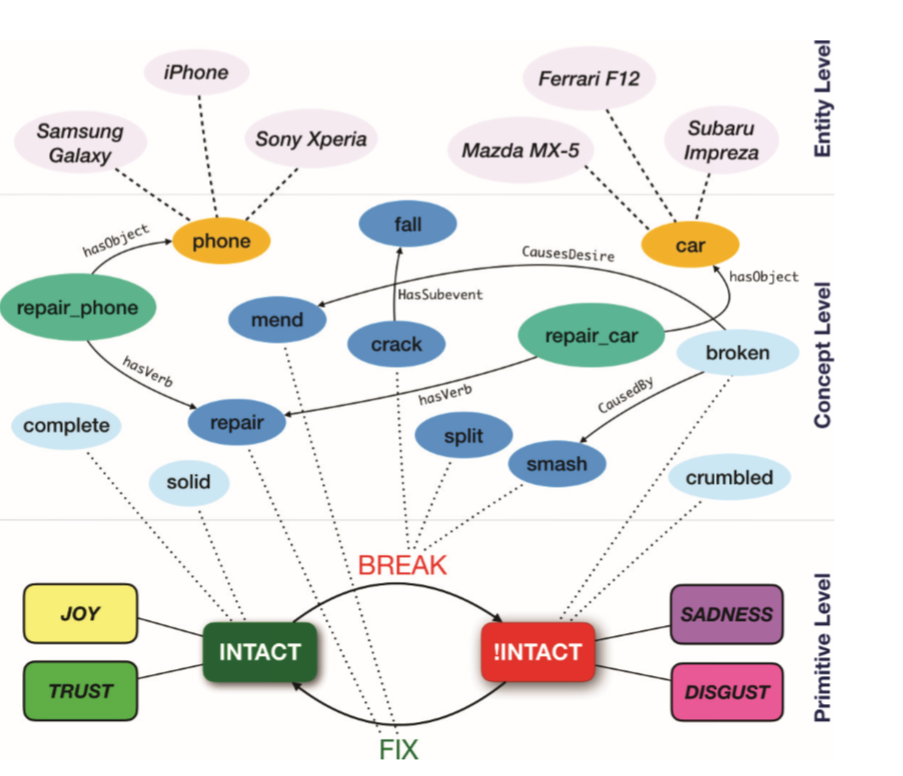
仔细研究这个图,我们就可以大概了解SenticNet5的思想。实体层的命名实体链接到常识性概念,通过深度学习发现的cluster被用来在概念级将这些原语与其词汇替代(常识性知识)联系起来。
基于SenticNet5 我们可以直接在原语层进行极性判断。当我们在原语层定义INTACT是positive之后,那么他的全部语法替代也将是positive,同时影响该极性结果的动词的极性也可以知道(如break的极性是negative,因为它将INTACT的极性变成negative),同时break的语法替代也是negative的,同时!INTACT的语法替代也是negative(比如crumbled)。
除了允许概念的泛化之外,概念原语还非常强大,可以动态地推断多字表达式的极性,就像代数乘法一样。例如,当将肯定结果动词INCREASE与肯定名词连接起来时,结果的极性是肯定的(例如,INCREASE_PLEASURE)。如果名词是负的,相反,结果的极性是负的(例如,INCREASE_LOSS)。
情感空间
为了自动推断关键状态的极性,例如INTACT,并对通过深度学习生成的cluster进行一致性检查,我们使用了情感空间,这是一个由随机投影构建的情感常识向量空间。随机投影是一种基于Johnson和Lindenstrauss引理的强大的降维技术(我们不将详述这一引理的理论细节)。利用随机投影的信息共享特性,具有相同语义效价和情感效价的概念可能具有相似的特征,即在情感空间中,传达相同含义的概念和情感倾向于彼此接近。相似性不取决于概念在向量空间中的绝对位置,而取决于概念与原点的夹角。因此,积极的概念,如快乐,庆祝和生日在向量空间的一个区域被发现,而消极的概念,如沮丧,哭泣,和损失在一个完全相反的区域被发现。
我们使用这个信息做两件事:其一,推断概念原语的极性,例如将INTACT的极性是positive因为包含它的cluster中大部分原语的概念是正的;其二,保持极性的一致性,丢弃那些和大多数极性相反的概念,例如,丢弃INTACT替代品中极性相反的概念。
