‘Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM’
—-本文发表于2018年AAAI会议
本文提出了一种通过使用常识性知识的新方法来解决targeted aspect-based情感分析问题,该问题包含aspect-based情感分析(分析对于不同aspect的情感)和targeted情感分析(给定target,分析情感)。本文提出了一种分层注意力机制的LSTM结构(target-level和sentence-level),同时将情感相关概念的常识性知识引入到深度神经网络的端到端训练中进行情感分类。
虽然现有的方法对于上述两个方面的情感分析已经有了不错的结果,然而仍然面临以下三个问题:
- 首先,对于给定的target,它可能有多个instance(实例,这里的意思是target多次出现)或者是一个multiple words,现有的做法认为所有instance同样重要,并简单的计算其平均值作为结果,这种简化往往会造成冲突。
- 其次,现有方法所利用的分层注意力只将与给定目标和aspect相关的情感词的推理隐式地建模为黑箱过程。
- 最后,现有的研究缺乏对深层神经网络外部知识的有效整合,如情感或常识知识,这些知识可以直接帮助识别aspect和情感极性。此外,如果没有任何约束,全局注意力模型可能倾向于编码与任务无关的信息。
本文的贡献主要体现在以下三点:
- 提出了一种分层注意力模型,该模型首先明确地关注target,然后再关注整个句子
- 我们扩展了经典的LSTM单元,其中包含了与外部知识集成的组件
- 我们将情感常识性知识整合到一个深度神经网络中。
Related work
我们简单的介绍一下情感分析的几个子问题:ABSA,targeted sentiment analysis。以及在深度神经模型中加入外部知识。
Aspect-Based Sentiment Analysis(ABAS)
ABAS就是要分析每个aspect的情感极性,该问题最大的挑战是如何在整个句子中表达指定aspect的情感信息。该部分的研究也是从最初的基于特征工程的方法到基于神经网络的方法,再到引入注意力机制(对于句子中的每个单词,注意力向量量化其情感显著性以及与给定aspect的相关性)。
Targeted Sentiment Analysis
该任务是要分析句子中给定目标实体的情感。因此针对性的情感分析方法是至关重要的,比如,目标依赖LSTM (TDLSTM)和目标连接LSTM(YCLSTM)对情感目标与整个句子之间的交互作用进行建模。
Incorporating External Knowledge
本文提出的模型,Sentic LSTM,受Xu等的启发(add a knowledge recall gate to the cell state of LSTM),不同之处在于,我们使用外部知识来生成hidden output并控制信息流。
Methodology
Task Definition
Targeted ABSA的任务定义如下:
对于句子s,我们将所有提到的同一个target视为一个target。对于由m个单词组成的target t,定义T={t1,t2,…tm},其中ti指t的第i个单词。Targeted ABSA的任务可以划分为两个子任务:首先,对于一个预定义的集合,找到t的aspect categories;其次,对于t找到它相对于每个aspect的情感。我们举一个例子来说明情况:
“I live in [West London] for years. I like it and it is safe to live in much of [west London]. Except [Brent] maybe. ”
该句子中包含两个target,WestLondon和Brent。我们的目标是检测aspect和对应的情感极性。在该例子中,对[WestLondon],输出是[‘general’:positive;’safety’:positive];对[Brent]的输出是[‘general’:negative;’safety’:negative]。这里的aspect指的是general和safety。
Overview
本文的神经网络架构分为两部分:序列编码器和分层注意力。结构示意图如下所示:
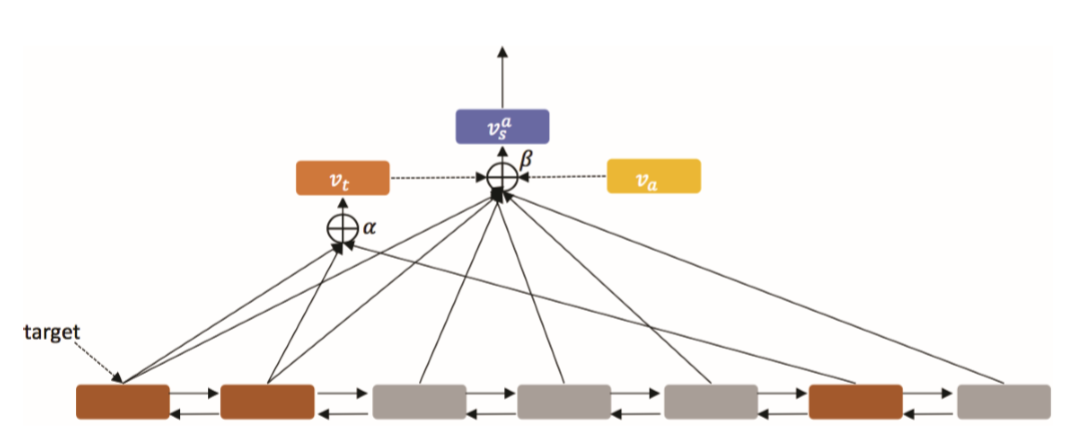
对于给定的句子,首先用一个BiLSTM进行编码;目标级注意力(target-level attention)将目标表达式位置上的hidden outputs作为输入(用棕色高亮显示),并在这些单词上计算一个自注意向量vt;然后,使用target representation(即vt)和aspect嵌入来计算句子级注意力(sentence-level attention);句子级注意力组件为每个aspect和target对返回一个句子向量;最后这个句子向量将被送到一个分类器中给出情感极性。
Target-level attention
这里我们先对上文提到的T={t1,t2,…tm}做进一步的说明,即ti可以是连续的也可以是非连续的,例如对于上文的例子中的target [West London]的T为T={3,4,20,21}。记T对应的hidden outputs为H’={ht1,ht2,…htm},则target t的向量表达vt为:
vt=H’$\alpha$=$\sum_{j}{\alpha_jh_{tj}}$
其中$\alpha$是target注意力向量,计算公式如下:
$\alpha$=softmax(W(2)atanh(W(1)aH’))
注意计算$\alpha$只使用了H’,而且H’的m是变化的(H’是dh x m维的),所以这里的W(1)a是dm x dh维的,W(2)a是1 x dm维的。
Sentence-Level Attention Model
有了target注意力向量,结合aspect嵌入,我们便可以获得句子最终的嵌入(target-and-aspect-specific,计算公式如下:
$v^{a}{s,t}=H\beta=\sum{i}{\beta_ih_i}$
其中H=[h1,….,hL],是BiLSTM的输出,$\beta$是句子级别注意力向量。a指定aspect,s指定句子,t指定目标。对于指定的aspect和t,$\beta$的计算公式如下:
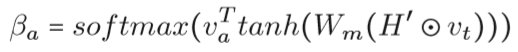
个人觉得作者对该公式的解释存在模糊的地方,顺着作者的意思,在这里揣测了一下作者的意图。首先,它将target的表达vt和每个隐藏层状态拼接了一下(concatenating),然后接上一个多层神经网络(一层或者两层带tanh激活函数的全连接层),得到的输出和aspect嵌入va相乘,最后接一个softmax。
Commonsense Knowledge
在本文中,使用SenticNet为我们引入常识性知识,在这个知识库中,“rotten fish”有“KindOf-food”的属性,这可以提供信息让我们使用类似“restaurant”、“food quality”之类的aspect(个人理解这里的aspect选取可以基于这样的规则,SenticNet对每个实体的属性有一个打分,例如“rotten fish”的“KindOf-food”的打分为0.922,那么我们可以根据这些打分来选择aspect)。除此之外,该常识库还可以提供情感信息,比如“rotten fish”的“Arises-joy”的打分为0。我们需要将这些信息编码到我们的模型中。
Sentic LSTM
Sentic LSTM试图赋予概念(concept)两个重要的作用:1)帮助过滤从一个时间步(time step)流向下一个时间步的信息;2)向记忆单元提供补充信息。
在第i个时间步,我们假设一个常识性概念候选集将被触发(triggered)并且映射到一个低维空间。(关于这个候选集作者没有详述如何生成,关于如何映射,作者应该是采用AffectiveSpace中的方法。)我们定义一个包含K个概念的集合{$\mu_{i,1},…,\mu_{i,k}$},首先对这个集合做一个combine,即:$\mu_i=\frac{1}{K}\sum_j\mu{i,j}$
作者提到这里的K至多为4。在介绍Sentic LSTM之前,我们先回顾一下LSTM以方便对比,LSTM的公式如下:
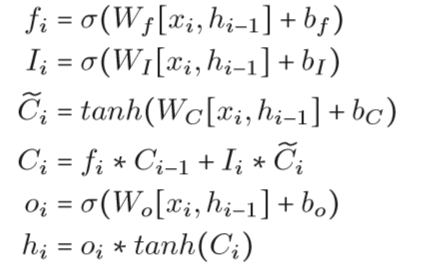
改进之后的Sentic LSTM公式如下:
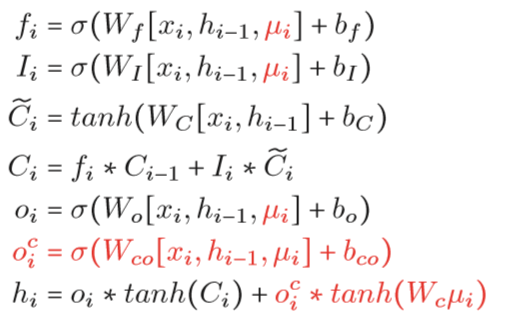
首先我们看到,作者假设情感概念(affective concepts)是控制token-level信息的有意义线索,于是$\mu_i$被用在各个门控单元中。其次,增加了一个知识输出门(knowledge output gate)$o^c_i$去输出概念级的知识(Wc$\mu_i$)。
实验
为了注入常识性知识,我们使用一个基于语法的概念分析器在每个时间步提取一组候选概念,并使用affecttivespace2作为概念嵌入。如果没有提取概念,则使用零向量作为概念输入。
