Context-Aware Representations for Knowledge Base Relation Extraction
—-本文发表于2017年的EMNLP会议。
这是一篇关于句子级别实体关系抽取的论文,考虑到传统方法只关注两个目标实体之间的关系而忽略句子中可能相关的其他关系,本文提出以一种新的框架。
Model architecture
Relation encoder
该部分的框架如下所示: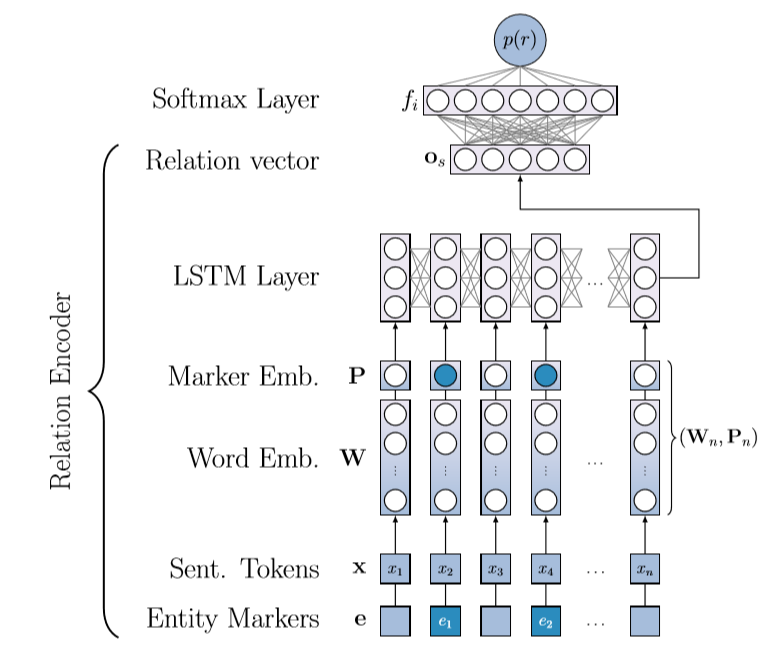
该部分比较简单,需要说明的是对实体标记的处理,和传统位置编码不同,对于句子内的每个单词,标记他属于第一个实体,第二个实体还是其他,对应的转化为一个3维的one-hot向量,再利用一个矩阵进行嵌入,最后将该位置编码和词向量拼接起来送给LSTM。
Model variants
1)LSTM baseline
直接将LSTM的最后一层输出送给全连接层和softmax层。
2)Context Sum
该部分的示意图是下所示:
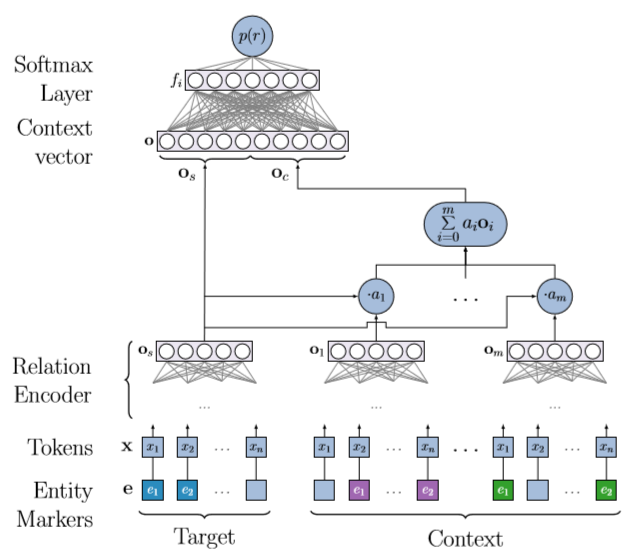
我们认为,为了预测目标实体对的关系类型,同一句话中的其他上下文关系是有用的。假设Os是目标实体对的编码输出,Oc是其他实体对编码输出的和,即$O_c=\sum{O_i}$,那么将O=[Os,Oc]送给softmax层得到输出。
3)ContextAtt
在上一种方法的基础山,该方法对其他实体对的编码做了加权(关系注意力机制),公式如下:
$O_c=\sum{a_iO_i},a_i=\frac{exp(g(O_i,O_s))}{\sum{exp(g(O_j,O_s))}}$
其中$g(O_i,O_s)=O_iAO_s$
